
人类的听觉具有神奇能力,闻声识人、听声辨物,往往也能从声音预测下一个动作,例如当你听到钥匙的碰撞声,会猜想有人即将打开门,声音能在脑中与各种想法建立连接,是对世界的探索及理解重要的能力。
让机器获得人类感官能力,以发展出更聪明的人工智能,一直是主流的看法,如自动驾驶,刷脸,物体识别是以视觉为主,也有许多科学家投入机器听觉的研究,广泛讨论的对象是自动语音识别(ASR),常见于智能语音助理,智能音箱等产品,相较于通过机器学习创造出各种新潮的应用,刺激民众消费,借其之力以改善某些群体生活上的不便利,或许更能彰显出 AI 的价值,机器学习改善助听器,就是一例。
苹果 AirPods 也想分杯羹?
调研机构 MarketsandMarkets 指出,全球助听器(含人工耳蜗)市场 2017 年规模大约 69.7 亿美元,2020 年预计将成长到 97.8 亿美元,接近百亿美元水平,需求成长主要来自老年人口增加。而在助听器领域有所谓的六大品牌,分别是丹麦的 GN ReSound,丹麦 William Demant 集团旗下的 Oticon,瑞士 Phonak 集团旗下的 Sonova,美国 Starkey,丹麦 Widex,以及从德国西门子分拆出来的 Sivantos,这六家公司就已经占据了全球超过 9 成的市占率。
就在两个月前,Widex 和 Sivantos 宣布合并,成为前三大助听器厂商,预计合并后的集团年销售额达 16 亿欧元。另外,助听器中使用的芯片则来自三大厂商:高通,恩智浦半导体 NXP(已被高通收购),安森美半导体(ON Semiconductor)。
虽然目前市场由上述六大巨头所把持,但他们也正面临着适应数字时代和更多精通技术公司的挑战,例如很想往医疗领域发展的苹果也默默尝试,目标把无线耳塞 AirPods 变成助听器,在今年开发者大会 WWDC,苹果释出 iOS 12 测试版,用户启用 Live Listen 辅助听力技术后,iPhone 就变为一个指向性麦克风,通过放大声音,让 AirPods 变成某种程度的听力辅助器。
助听器是属于一种医疗器材,必须经过完整且漫长的医事检验流程,这往往也是许多电子产品业者想进军医疗器材会遭遇的挑战,当然,苹果也并非过度乐观,主要是美国在 2017 年 8 月通过一项具指标性意义的新法,美国食品和药物管理局(FDA)为中度至轻度听力受损的人新增加一项“非处方”、也就是可临柜购买(OTC,Over-The-Counter)的可穿戴听力设备类别,同时 FDA 有 3 年的时间来完成 OTC 听力设备的规章制度。
此类助听器不同于传统助听器需要通过 FDA 医疗器材等级的认证,但仍需要符合 FDA 的监管规章,有些轻度症状的人未来不需到特定机构进行验配,可以直接在零售通路购买助听器,类似老花眼镜一样,由于市场商机可期,让许多电子设备厂商摩拳擦掌展开布局。
助听器里的机器学习
另一方面,现有助听器仍有许多变革空间,包括声音品质、使用体验、价格,使用机器学习来改善现有相关技术,已经是行业兴起的趋势,像是基于深度学习的多模态语音增强、以深度神经网络分类分离语音和噪声、以深度学习优化降噪等,都能见到大企业跟初创公司投入,如知名的助听器品牌 Widex、初创企业如由美国俄亥俄州立大学教授汪德亮担任首席科学家的大象声科、或是团队来自芯片公司如联发科、恩智浦半导体的 RelaJet 等。
现有助听器主要有两个层面的问题,第一个是技术,其次是成本。
助听器主要由三大元件构成:麦克风、扩大器(amplifier)及接收器。简单来说,现有绝大多数助听器的处理流程是前处理+声音处理+后处理,根据 FDA 的规定,声音从助听器的麦克风收音进来、算法处理、到喇叭播放出声音,整个流程只有 10 毫秒(ms)的处理时间,之所以有不得超过 10ms 的原因在于声音延迟太久,容易导致助听器用户出现头晕、不舒服的现象,概念就像是配戴 VR 头显一样,视觉影像的延迟也会导致用户体验不佳。
所谓的前处理包括把声音转为数位讯号、降噪等,而后处理的工作则有语音合成等,前、后处理分别会占用 1~2ms 的时间,扣除之后,只留有 5~6ms 给算法进行声音处理,正因为处理的时间相当受限,能做的事就不多,所以过去 20~30 年助听器的研究多围绕在移频、声音放大、降噪,或是体积的缩小、芯片功耗的减少、增加 2.4 GHz、蓝牙无线连结功能等。
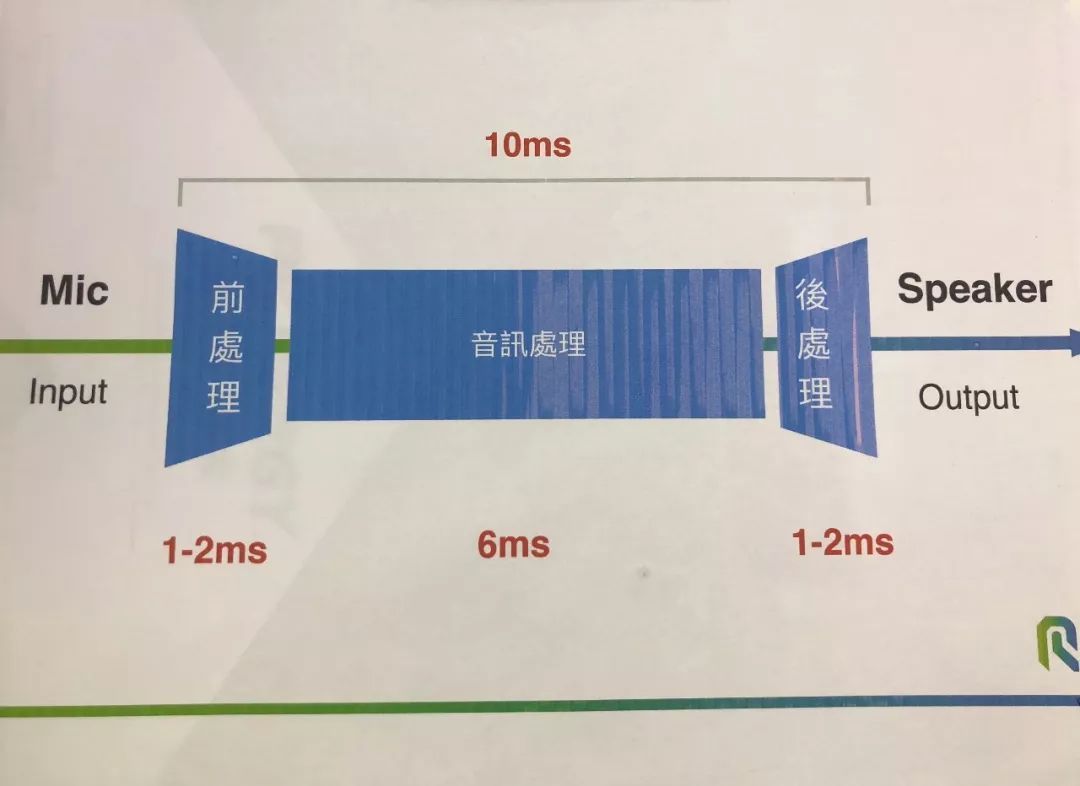
图|现有多数助听器的处理流程。
说话大声的人不一定对用户有意义
再加上,传统助听器的设计逻辑较为过时,助听器多是针对讲话比较大声的那一个人的声音放大,但讲话比较大声的人对助听器佩戴者来说,就代表比较重要吗?很可能不是,佩戴者或许会更想听清楚家人、朋友、同事所讲的话,所以这种应用场景需求的设想是存在误解的。此外,助听器使用的传统算法多半无法同时分离太多人的声音。
再来就是价格昂贵,助听器的价格范围颇大,依功能、厂牌从 1000~5000 美元不等,除了设备之外,还有耗材如电池的开销。尽管助听器的预期使用寿命大约是 5 年,高于一般消费电子产品,但对一般人来说仍是一笔不小的负担。
RelaJet 创始人陈柏儒本身就是一名助听器的佩戴者,知道听障者在日常沟通上会遇到何种困扰,痛点是什么。他就举例表示,假设在咖啡厅里,每个人讲话的声音频率,能量都接近时,就会对听障者非常困扰,因为很不容易从助听器放大的 2D 声音中专注其中一个人的声音。另外,一般助听器多只能做单一人声的辨别,有时甚至还会把噪音加强。同时还有产品价格的助听器成本高低问题,“我配戴的助听器,一个耳朵就要价 4666 美元,以及每一周花 1 美元更换电池”。
先前任职联发科的陈柏儒,做的就是芯片设计,基于机器学习开发出一个“人声分离引擎”,来解决上述的技术性问题,并与在中国国内担任律师的哥哥陈宥任一起创业,其他核心技术成员都是来自联发科、恩智浦等知名芯片公司。
传统的人声分离作法
过去在多人声分离领域,大致可归类两种作法:
一是采集大量的个人语音音档,透过声纹、频率分离,目前在国际论文上,做到比较好的准确度以 2 人分离或者是 3 人分离为主。目前这种做法需要花大量的时间做客制化声音的训练。
二是透过物理麦克风阵列。主要是透过麦克风摆放的物理性解决问题,基本上用两只麦克风就能算出角位差,透过这样的差距可以设计模型透过声音的差异去分辨人的声纹、方向等,但是两只麦克风有一个问题就是彼此距离稍微长,所以开始有人研究 3 只以上的策略,来缩小终端装置的体积,不过普遍来看会有一个问题,当两个频率接近、而且站得近的人会不太容易分离,因此分离出来的声音可能还是会遇上体验不佳的情形。
RelaJet 的技术之所以引人注目,在于他们开发一套神经网络引擎,直接让声音的 PCM 档进去这个引擎,而输出也是 PCM 输出,少掉了上述的前处理和后处理,所以有完整的 10 ms 时间做声音处理。
例如在“多人”人声场景下,能把每个人的声音分离达到 6~8 成的准确度,最初训练出来的模型只能做到 6 成准确度,后来他们使用生成对抗式网络(GAN)做补强,近一步提高到 8 成,而剩下的 2 成,原因在于大多数人说话的声音频率都很接近,想要百分之百辨识仍有一定难度,但相较于传统助听器在多人人声的环境,分离准确度大概只能做到 3~4 成,效果已经翻了一倍。
另外,陈柏儒表示,不同语言会影响助听器收音的调教,而且亚洲人的对话中又特别常出现中英文夹杂的特色,这也需要对模型进行特别的训练,RelaJet 训练的模型就是锁定亚洲市场需求。对于近一步技术细节,RelaJet 将在近一个月发表论文,对外公开。

图| RelaJet 的方案拿掉前处理和后处理,让声音直接进入神经网络引擎
英国心理学家 Colin Cherry 在 60 年代提出人类听觉有选择能力的特质,比如在一个派对上夹杂着众人谈话的声音、音乐声、酒杯碰撞声,但是在这些环境音的干扰下,人类还是可以针对与自己相关或是注意的声音特别关注,像是当有人喊你的名字,你依旧听得清楚。因此科学家及行业人士一直希望能突破智能音箱、服务型机器人、甚至是助听器的鸡尾酒派对问题,以改善这些设备的使用体验。
而 RelaJet 提供了一个方式提升助听器识别某些人声的能力,使用者利用手机 APP 录制 3~5 秒钟的声源,上传系统进行声音特征分析、作为标注特定人声后,就会自动把更新后的模型部署到助听器上,也就是说,用户可以自订,针对某些比较有意义的人声进行特别放大,像是家人、男女朋友,就可以在吵杂的人声之中相对听清楚对方的声音。另一个好处就是无需再跑到医院调校助听器,也不用像向传统助听器得预录 2~3 小时的录音档,现在只要 3~5 秒就行。“如此可解决一定程度的鸡尾酒派对问题”。
至于可以预录多少人声,“取决于硬体的资源,资源越多就可以预录越多人,但是以使用者的需求来说,强化特定 2~3 个人的声音,大致上就可以满足,”陈柏儒说。另外,RelaJet 的 APP 也可以让用户切换情境,例如家里、办公室,助听器就会针对个别环境进行较适合的声音处理细节。
对初创公司来说,要直接与助听器品牌竞争,是一件困难且漫长的路,不仅医疗仪器验证时间长,还得打通与医院、诊所等医疗生态圈的关系,RelaJet 清楚自己的强项在于芯片设计+算法,所以他们不做助听器,而是提供 Turnkey Solution 给助听器品牌或是医疗设备的芯片商,声音运算都在 edge 端(也就是助听器)做即时处理,因此 AI 算法如何做得精简又准确,但又要做到硬体平台的驱动,这就是他们比传统的声音算法公司更具有优势的地方。
在 IC 设计行业多年的陈柏儒就指出,现有助听器都是采用高阶的芯片,价格偏高,但在这一波机器学习浪潮下,可以通过新式算法提升助听器的声音处理的能力,只要搭配使用中阶的芯片,就能够改善整体助听器的品质,“我们的目标是做到现有助听器 1/3 的价格”。助听器知识
Copyright ©2013–2024 厦门艾声听力科技连锁有限公司 闽ICP备12006824号-3
免责声明

